# Import all required libraries
# Data handling and manipulation
import pandas as pd
import numpy as np
# Implementing and selecting models
import statsmodels.api as sm
from sklearn.model_selection import train_test_split, cross_val_score, KFold
from itertools import combinations
from mlxtend.feature_selection import SequentialFeatureSelector as SFS
from sklearn.linear_model import LinearRegression
# For advanced visualizations
import matplotlib.pyplot as plt
import seaborn as sns
# Show computation time
import time
# Increase font size of all Seaborn plot elements
sns.set(font_scale = 1.25)
# Set Seaborn theme
sns.set_theme(style = "white")Regressions I
Data Mining and Discovery
Linear regression
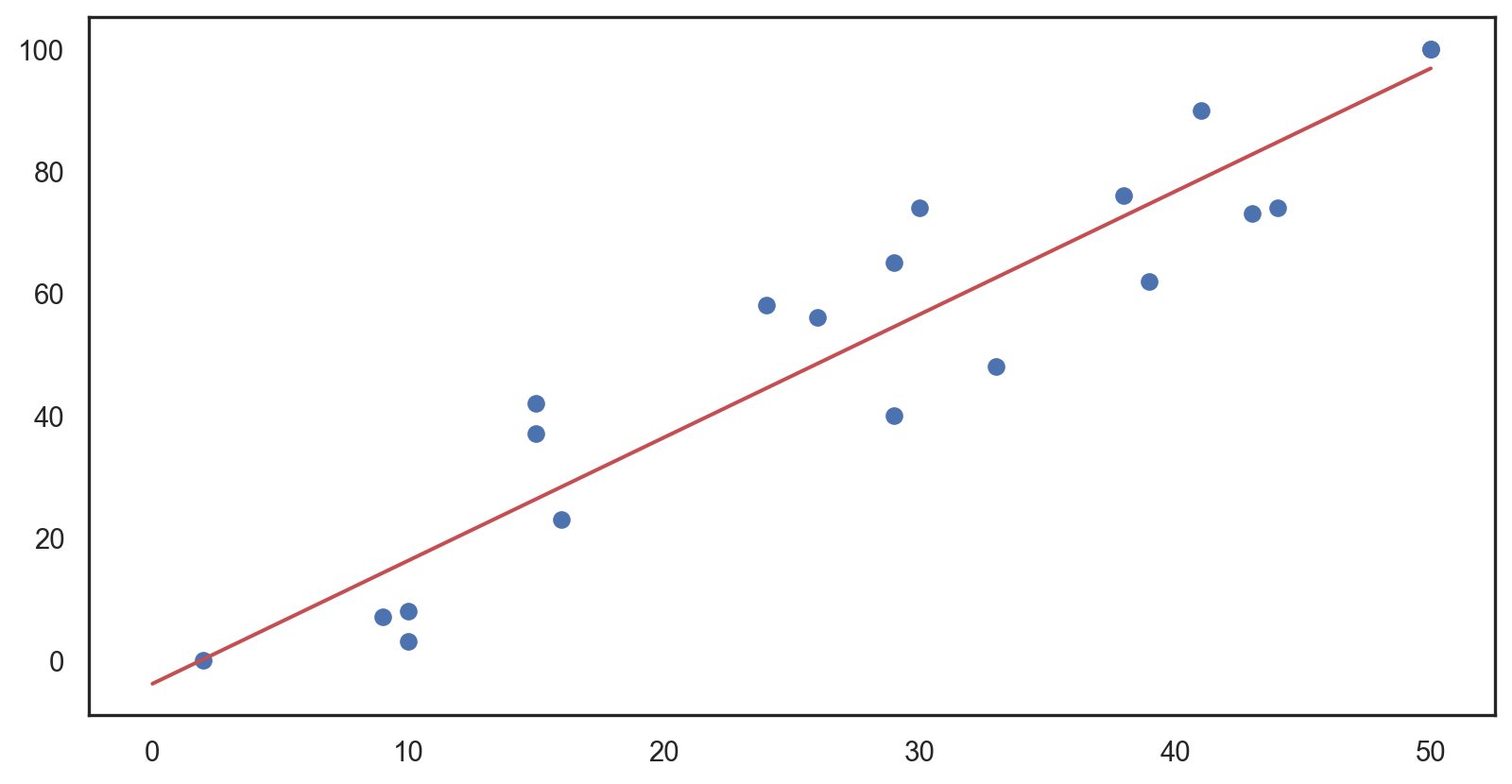
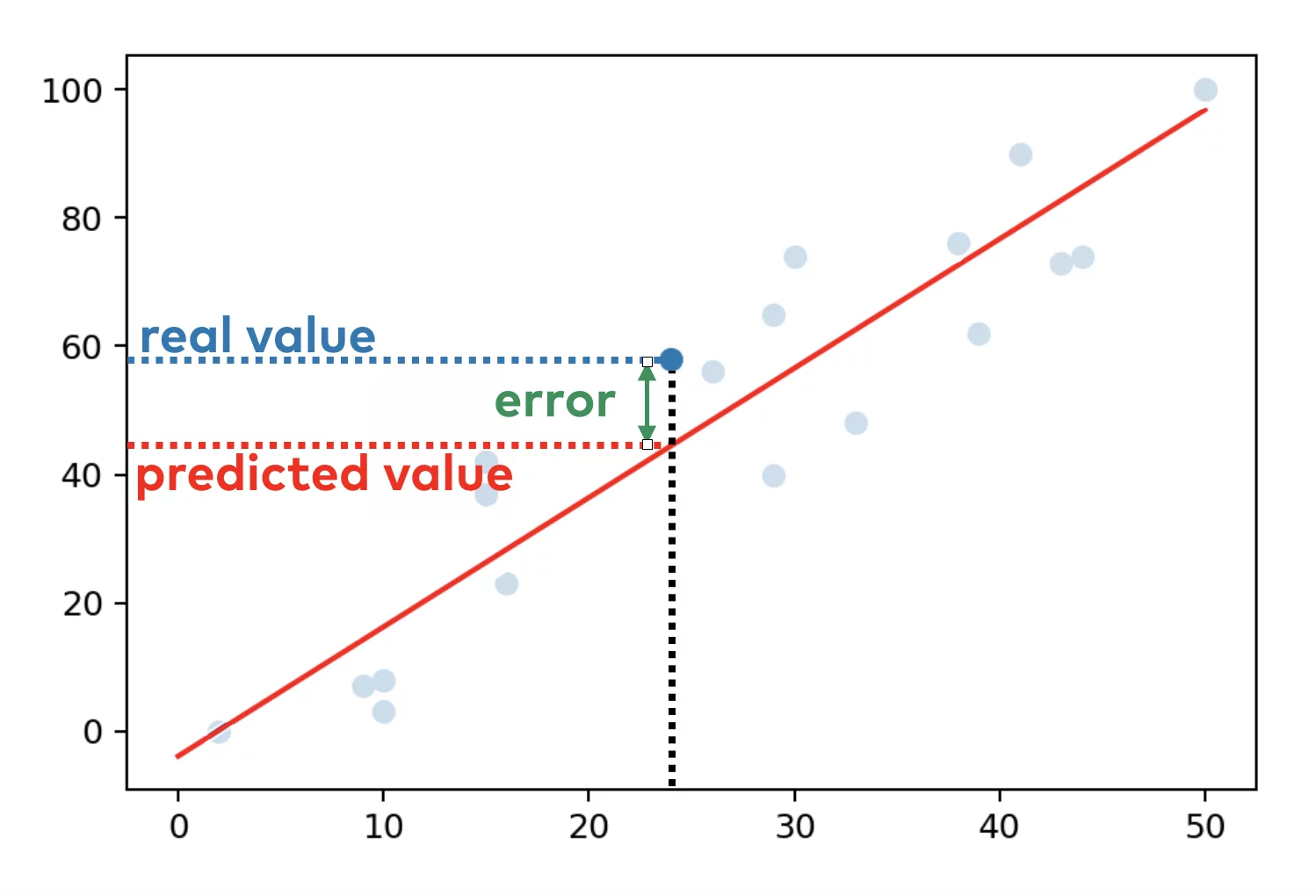
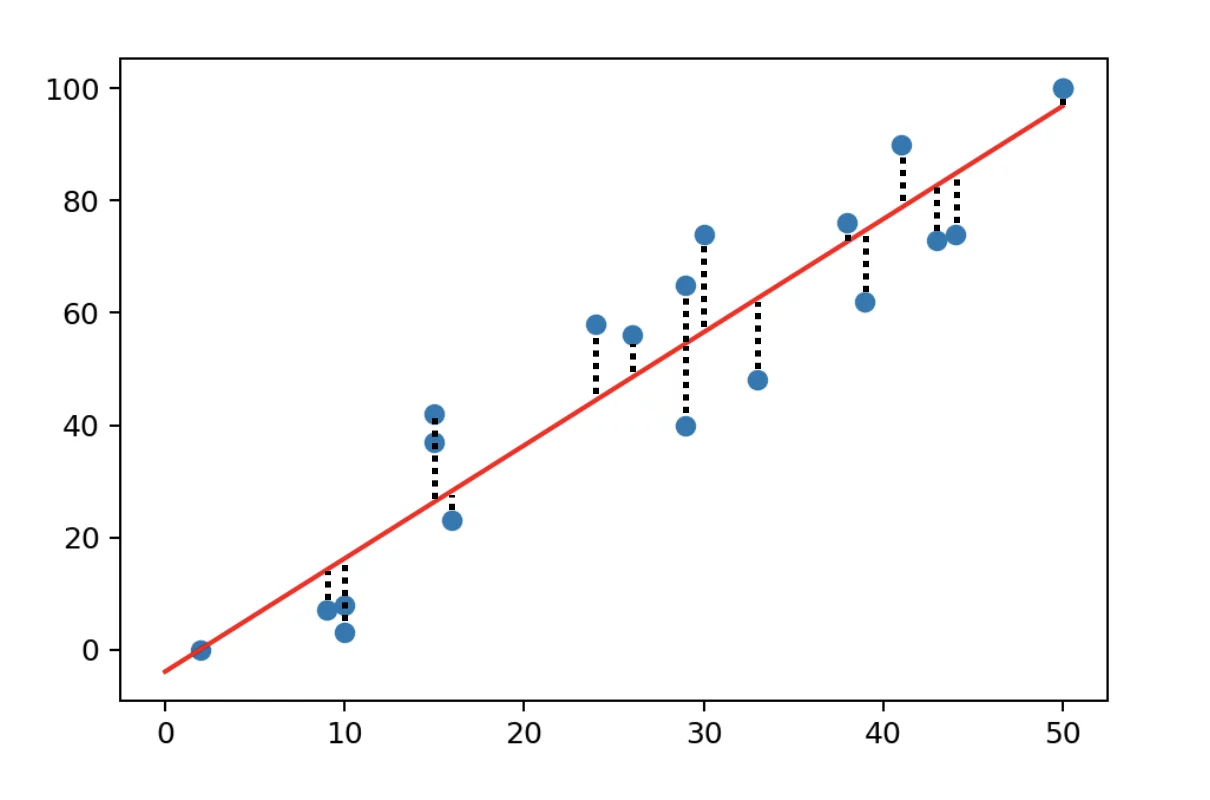
Objective: Minimize the sum of squared differences between observed and predicted.
Model structure:
\(Y_i = \beta_0 + \beta_1 X_i + \epsilon_i\)
\(Y_i\): Dependent/response variable
\(X_i\): Independent/predictor variable
\(\beta_0\): y-intercept
\(\beta_1\): Slope
\(\epsilon_i\): Random error term, deviation of the real value from predicted
Assumptions: Linearity, independent residuals, constant variance (homoscedasticity), and normally distributed residuals.
Goodness of Fit: Assessed by \(R^2\), the proportion of variance in \(Y\) explained by \(X\).
Statistical Significance: Tested by t-tests on the coefficients.
Confidence Intervals: Provide a range for the estimated coefficients.
Predictions: Use the model to predict \(Y\) for new \(X\) values.
Diagnostics: Check residuals for model assumption violations.
Sensitivity: Influenced by outliers which can skew the model.
Applications: Used across various fields for predictive modeling and data analysis.
Assumptions
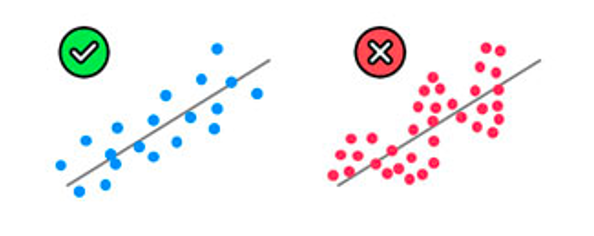
Linearity
(Linear relationship between Y ~ X)
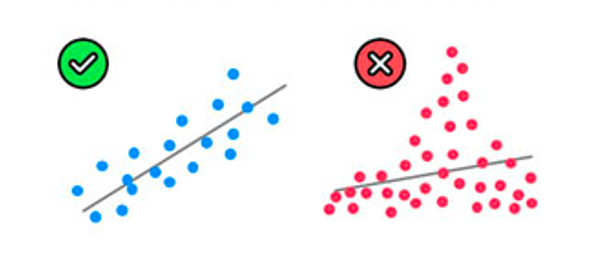
Homoscedasticity
(Equal variance among variables)
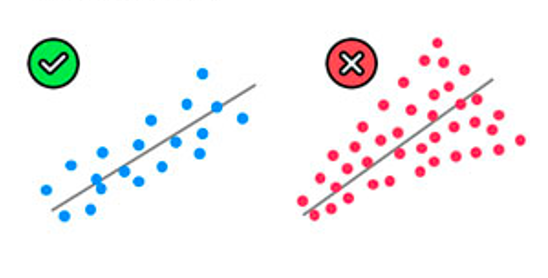
Multivartiate Normality
(Normally distributed residuals)
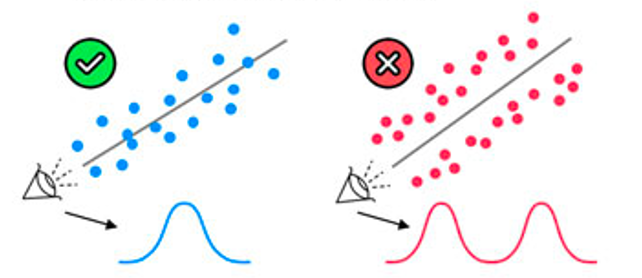
Independence
(Observations are independent)
Lack of Multicollinearity
(Predictors are not correlated)
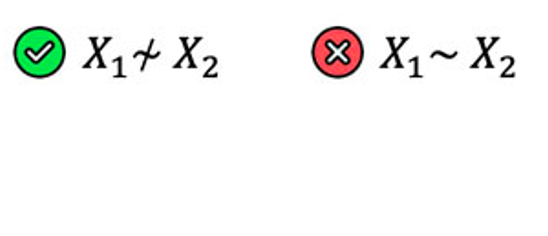
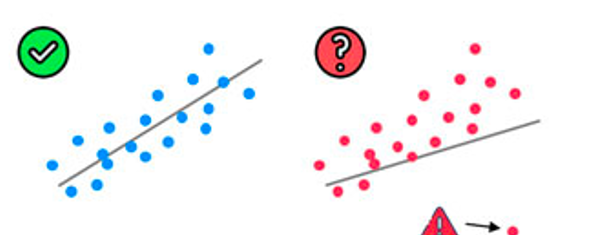
Outlier check
(Technically not an assumption)
Ordinary Least Squares (OLS)
\(\displaystyle y_{i}=\beta_{1} x{i_1}+\beta_{2} x{i_2}+\cdots +\beta_{p} x{i_p}+\varepsilon _{i}\)
- \(y_i\): Dependent variable for the \(i\)-th observation.
- \(\beta_1, \beta_2, …, \beta_p\): Coefficients representing the impact of each independent variable.
- \(x_{i1}, x_{i1},…, x_{ip}\): Independent variables for the \(i\)-th observation.
- \(\epsilon_i\): Error term for the \(i\)-th observation, indicating unexplained variance.
Assessing accuracy of model
Three major methods:
- Mean square error (MSE): MSE of a predictor is calculated as the average of the squares of the errors, where the error is the difference between the actual value and the predicted value.
- R-squared (\(R^2\)): Proportion of variance in the dependent variable explained by the model; closer to 1 indicates a better fit.
- Adjusted R-squared (\(R^2_{adj}\)): Modified R² that accounts for the number of predictors; useful for comparing models with different numbers of independent variables.
- Residual plots: Visual check for randomness in residuals; patterns may indicate model issues like non-linearity or heteroscedasticity.
In statistics, the mean squared error (MSE) or mean squared deviation (MSD) of an estimator measures the average of the squares of the errors—that is, the average squared difference between the estimated values and the actual value. The MSE either assesses the quality of a predictoror of an estimator.
Predictor
\(MSE = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\)
\(y_i\): the actual values
\(\hat{y}_i\): the predicted values
\(n\): sample size
Define the residuals as \(e_i = y_i − f_i\)(forming a vector \(e\)).
If \(\bar{y}\) is the observed mean:
\(\bar{y}=\frac{1}{n} \sum_{i=1}^{n}y_i\)
then the variability of the data set can be measured with two sums of squares (SS) formulas:
\(RSS = \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\)
\(TSS = \sum_{i=1}^{n} (y_i - \bar{y})^2\)
R-squared:
\(R^2 = 1 - \frac{RSS}{TSS}\)
Formula \(R^2 = 1 - \frac{RSS / df_{res}}{TSS / df_{tot}}\)
Key points:
Penalizes Complexity: Adjusts for the number of terms in the model, penalizing the addition of irrelevant predictors.
Comparability: More reliable than R-squared for comparing models with different numbers of independent variables.
Value Range: Can be negative if the model is worse than using just the mean of the dependent variable, whereas R-squared is always between 0 and 1.
- \(df_{res}\): degrees of freedom of the estimate of the population variance around the model
- \(df_{tot}\): degrees of freedom of the estimate of the population variance around the mean
Our data
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 50 entries, 0 to 49
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 family_income 50 non-null float64
1 gift_aid 50 non-null float64
2 price_paid 50 non-null float64
dtypes: float64(3)
memory usage: 1.3 KB| family_income | gift_aid | price_paid | |
|---|---|---|---|
| count | 50.000000 | 50.000000 | 50.000000 |
| mean | 101.778520 | 19.935560 | 19.544440 |
| std | 63.206451 | 5.460581 | 5.979759 |
| min | 0.000000 | 7.000000 | 8.530000 |
| 25% | 64.079000 | 16.250000 | 15.000000 |
| 50% | 88.061500 | 20.470000 | 19.500000 |
| 75% | 137.174000 | 23.515000 | 23.630000 |
| max | 271.974000 | 32.720000 | 35.000000 |
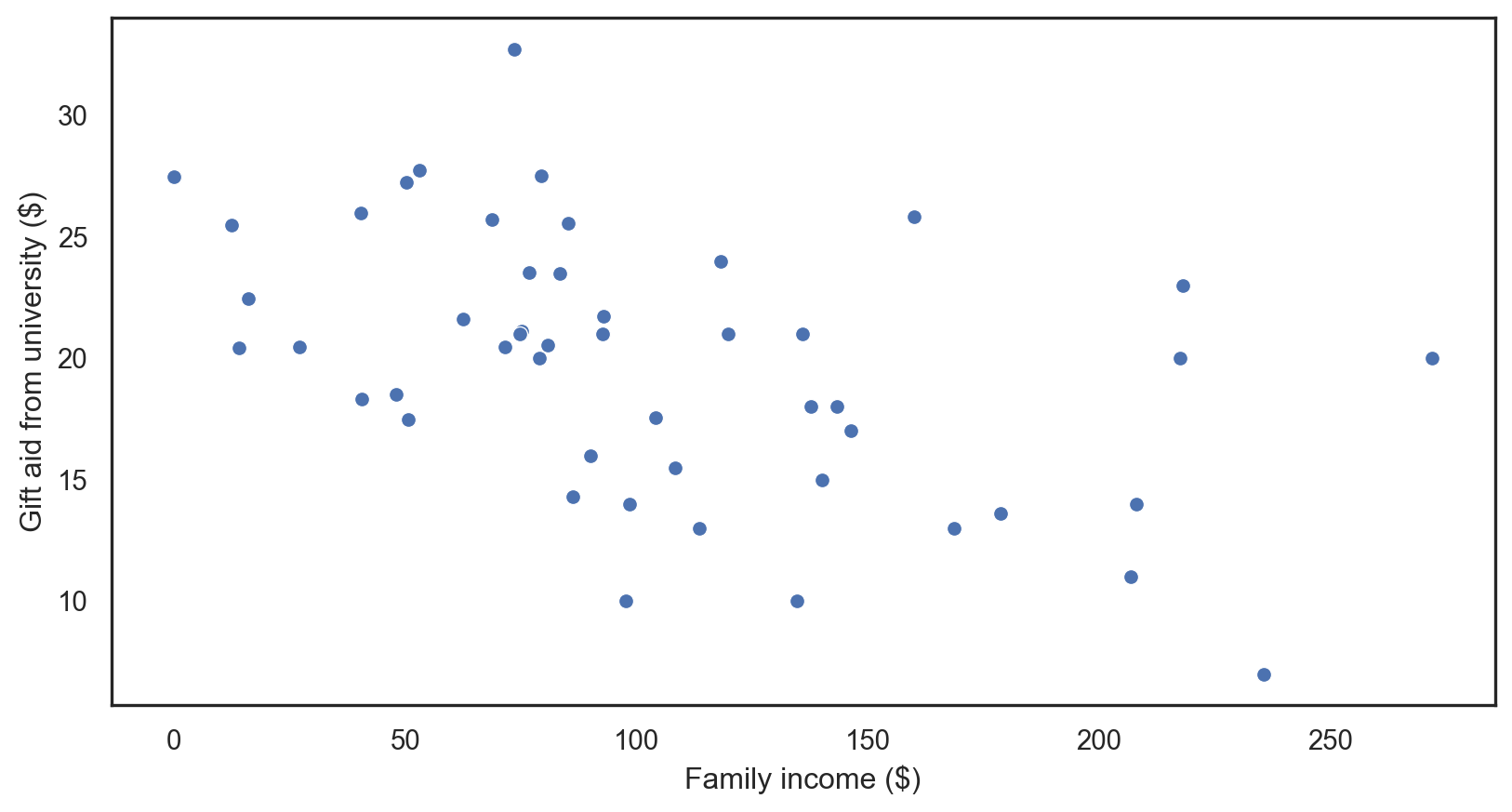
OLS regression: applied
Code
X = elmhurst['family_income'] # Independent variable
y = elmhurst['gift_aid'] # Dependent variable
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
X_train_with_const = sm.add_constant(X_train)
model = sm.OLS(y_train, X_train_with_const).fit()
model_summary2 = model.summary2()
print(model_summary2) Results: Ordinary least squares
=================================================================
Model: OLS Adj. R-squared: 0.205
Dependent Variable: gift_aid AIC: 241.3545
Date: 2026-02-03 13:07 BIC: 244.7323
No. Observations: 40 Log-Likelihood: -118.68
Df Model: 1 F-statistic: 11.05
Df Residuals: 38 Prob (F-statistic): 0.00197
R-squared: 0.225 Scale: 23.273
-----------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
-----------------------------------------------------------------
const 24.5170 1.4489 16.9216 0.0000 21.5839 27.4500
family_income -0.0398 0.0120 -3.3238 0.0020 -0.0640 -0.0156
-----------------------------------------------------------------
Omnibus: 0.057 Durbin-Watson: 2.277
Prob(Omnibus): 0.972 Jarque-Bera (JB): 0.249
Skew: 0.047 Prob(JB): 0.883
Kurtosis: 2.625 Condition No.: 230
=================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the
errors is correctly specified.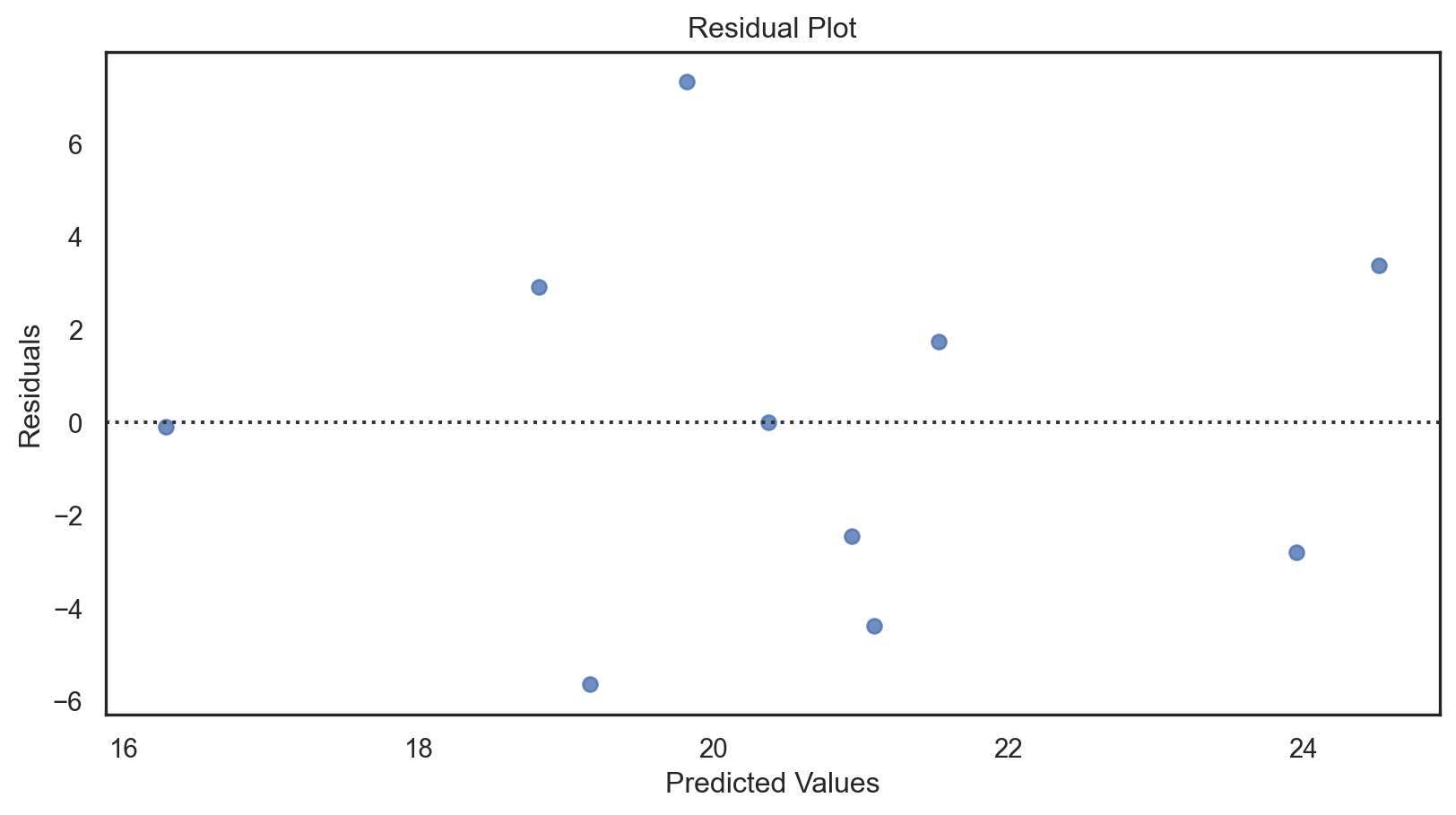
Code
plt.scatter(X_test, y_test, label = 'Data')
line_x = np.linspace(X_test.min(), X_test.max(), 100)
line_y = model.predict(sm.add_constant(line_x))
plt.plot(line_x, line_y, color = 'red', label = 'OLS Regression Line')
plt.xlabel("Family income ($)")
plt.ylabel("Gift aid from university ($)")
plt.title('OLS Regression Fit')
plt.legend()
plt.show()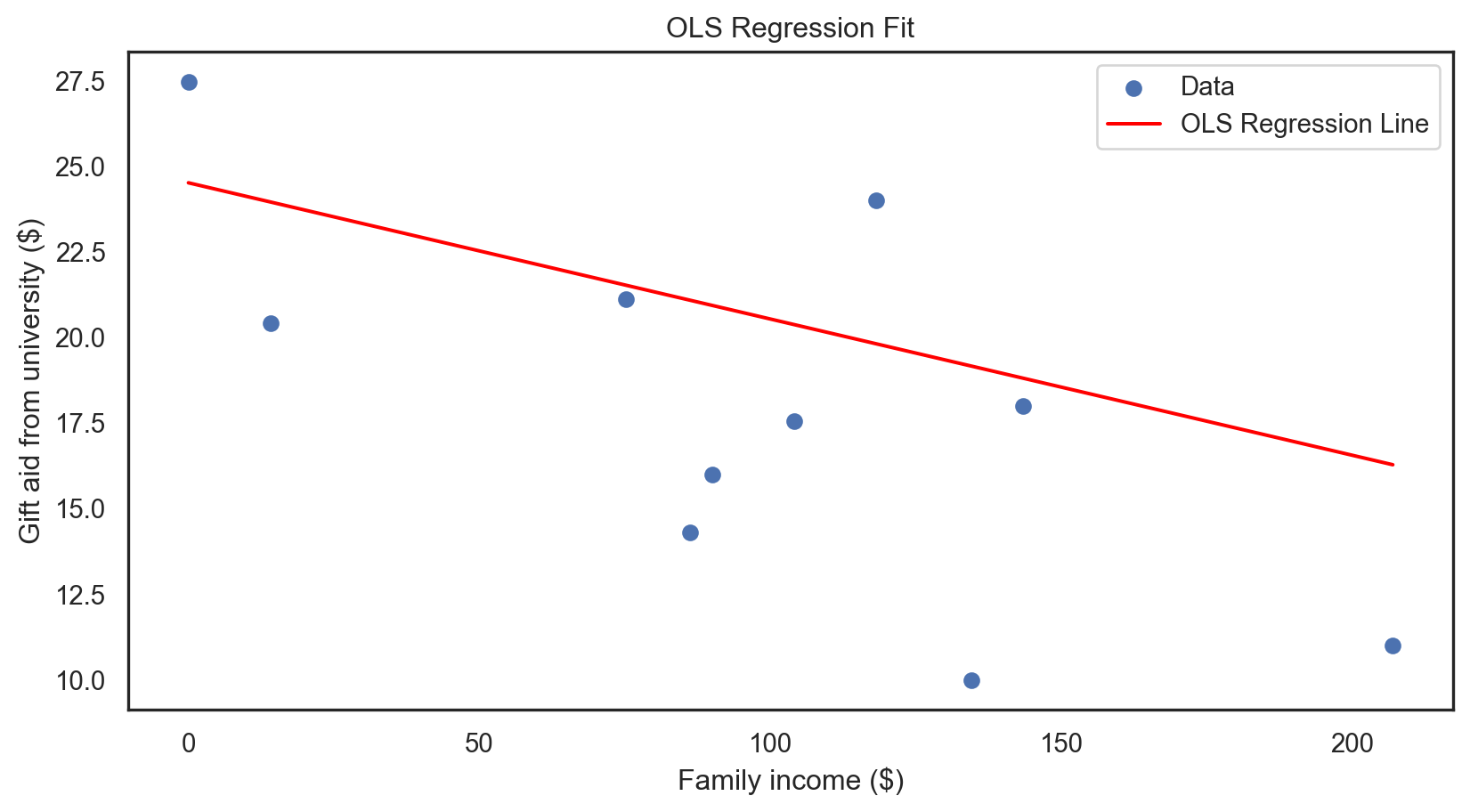
Multiple regression
Multiple Predictors: more than one predictor variable to predict a response variable.
Model Form: \(Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \cdots + \beta_n X_n + \epsilon\) , where \(Y\) is the response variable, \(X_1, X_2,...,X_n\) are predictor variables, \(\beta\)s are coefficients, and \(\epsilon\) is the error term.
Coefficient Interpretation: Each coefficient represents the change in the response variable for one unit change in the predictor, holding other predictors constant.
Assumptions: Includes linearity, no perfect multicollinearity, homoscedasticity, independence of errors, and normality of residuals.
Adjusted R-squared: Used to determine the model’s explanatory power, adjusting for the number of predictors.
Multicollinearity Concerns: High correlation between predictor variables can distort the model and make coefficient estimates unreliable.
Interaction Effects: Can be included to see if the effect of one predictor on the response variable depends on another predictor.
Our data
How do factors like debt-to-income ratio, bankruptcy history, and loan term affect the interest rate of a loan?

| emp_title | emp_length | state | homeownership | annual_income | verified_income | debt_to_income | annual_income_joint | verification_income_joint | debt_to_income_joint | ... | sub_grade | issue_month | loan_status | initial_listing_status | disbursement_method | balance | paid_total | paid_principal | paid_interest | paid_late_fees | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | global config engineer | 3.0 | NJ | MORTGAGE | 90000.0 | Verified | 18.01 | NaN | NaN | NaN | ... | C3 | Mar-2018 | Current | whole | Cash | 27015.86 | 1999.33 | 984.14 | 1015.19 | 0.0 |
| 1 | warehouse office clerk | 10.0 | HI | RENT | 40000.0 | Not Verified | 5.04 | NaN | NaN | NaN | ... | C1 | Feb-2018 | Current | whole | Cash | 4651.37 | 499.12 | 348.63 | 150.49 | 0.0 |
| 2 | assembly | 3.0 | WI | RENT | 40000.0 | Source Verified | 21.15 | NaN | NaN | NaN | ... | D1 | Feb-2018 | Current | fractional | Cash | 1824.63 | 281.80 | 175.37 | 106.43 | 0.0 |
| 3 | customer service | 1.0 | PA | RENT | 30000.0 | Not Verified | 10.16 | NaN | NaN | NaN | ... | A3 | Jan-2018 | Current | whole | Cash | 18853.26 | 3312.89 | 2746.74 | 566.15 | 0.0 |
| 4 | security supervisor | 10.0 | CA | RENT | 35000.0 | Verified | 57.96 | 57000.0 | Verified | 37.66 | ... | C3 | Mar-2018 | Current | whole | Cash | 21430.15 | 2324.65 | 1569.85 | 754.80 | 0.0 |
5 rows × 55 columns
| Variable | Description |
|---|---|
interest_rate |
Interest rate on the loan, in an annual percentage. |
verified_income |
Borrower’s income verification: Verified, Source Verified, and Not Verified. |
debt_to_income |
Debt-to-income ratio, which is the percentage of total debt of the borrower divided by their total income. |
credit_util |
The fraction of available credit utilized. |
bankruptcy |
An indicator variable for whether the borrower has a past bankruptcy in their record. This variable takes a value of 1 if the answer is yes and 0 if the answer is no. |
term |
The length of the loan, in months. |
issue_month |
The month and year the loan was issued. |
credit_checks |
Number of credit checks in the last 12 months. |
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10000 entries, 0 to 9999
Data columns (total 55 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 emp_title 9167 non-null object
1 emp_length 9183 non-null float64
2 state 10000 non-null object
3 homeownership 10000 non-null object
4 annual_income 10000 non-null float64
5 verified_income 10000 non-null object
6 debt_to_income 9976 non-null float64
7 annual_income_joint 1495 non-null float64
8 verification_income_joint 1455 non-null object
9 debt_to_income_joint 1495 non-null float64
10 delinq_2y 10000 non-null int64
11 months_since_last_delinq 4342 non-null float64
12 earliest_credit_line 10000 non-null int64
13 inquiries_last_12m 10000 non-null int64
14 total_credit_lines 10000 non-null int64
15 open_credit_lines 10000 non-null int64
16 total_credit_limit 10000 non-null int64
17 total_credit_utilized 10000 non-null int64
18 num_collections_last_12m 10000 non-null int64
19 num_historical_failed_to_pay 10000 non-null int64
20 months_since_90d_late 2285 non-null float64
21 current_accounts_delinq 10000 non-null int64
22 total_collection_amount_ever 10000 non-null int64
23 current_installment_accounts 10000 non-null int64
24 accounts_opened_24m 10000 non-null int64
25 months_since_last_credit_inquiry 8729 non-null float64
26 num_satisfactory_accounts 10000 non-null int64
27 num_accounts_120d_past_due 9682 non-null float64
28 num_accounts_30d_past_due 10000 non-null int64
29 num_active_debit_accounts 10000 non-null int64
30 total_debit_limit 10000 non-null int64
31 num_total_cc_accounts 10000 non-null int64
32 num_open_cc_accounts 10000 non-null int64
33 num_cc_carrying_balance 10000 non-null int64
34 num_mort_accounts 10000 non-null int64
35 account_never_delinq_percent 10000 non-null float64
36 tax_liens 10000 non-null int64
37 public_record_bankrupt 10000 non-null int64
38 loan_purpose 10000 non-null object
39 application_type 10000 non-null object
40 loan_amount 10000 non-null int64
41 term 10000 non-null int64
42 interest_rate 10000 non-null float64
43 installment 10000 non-null float64
44 grade 10000 non-null object
45 sub_grade 10000 non-null object
46 issue_month 10000 non-null object
47 loan_status 10000 non-null object
48 initial_listing_status 10000 non-null object
49 disbursement_method 10000 non-null object
50 balance 10000 non-null float64
51 paid_total 10000 non-null float64
52 paid_principal 10000 non-null float64
53 paid_interest 10000 non-null float64
54 paid_late_fees 10000 non-null float64
dtypes: float64(17), int64(25), object(13)
memory usage: 4.2+ MB| emp_length | annual_income | debt_to_income | annual_income_joint | debt_to_income_joint | delinq_2y | months_since_last_delinq | earliest_credit_line | inquiries_last_12m | total_credit_lines | ... | public_record_bankrupt | loan_amount | term | interest_rate | installment | balance | paid_total | paid_principal | paid_interest | paid_late_fees | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 9183.000000 | 1.000000e+04 | 9976.000000 | 1.495000e+03 | 1495.000000 | 10000.00000 | 4342.000000 | 10000.00000 | 10000.00000 | 10000.000000 | ... | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 | 10000.000000 |
| mean | 5.930306 | 7.922215e+04 | 19.308192 | 1.279146e+05 | 19.979304 | 0.21600 | 36.760709 | 2001.29000 | 1.95820 | 22.679600 | ... | 0.123800 | 16361.922500 | 43.272000 | 12.427524 | 476.205323 | 14458.916610 | 2494.234773 | 1894.448466 | 599.666781 | 0.119516 |
| std | 3.703734 | 6.473429e+04 | 15.004851 | 7.016838e+04 | 8.054781 | 0.68366 | 21.634939 | 7.79551 | 2.38013 | 11.885439 | ... | 0.337172 | 10301.956759 | 11.029877 | 5.001105 | 294.851627 | 9964.561865 | 3958.230365 | 3884.407175 | 517.328062 | 1.813468 |
| min | 0.000000 | 0.000000e+00 | 0.000000 | 1.920000e+04 | 0.320000 | 0.00000 | 1.000000 | 1963.00000 | 0.00000 | 2.000000 | ... | 0.000000 | 1000.000000 | 36.000000 | 5.310000 | 30.750000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 | 0.000000 |
| 25% | 2.000000 | 4.500000e+04 | 11.057500 | 8.683350e+04 | 14.160000 | 0.00000 | 19.000000 | 1997.00000 | 0.00000 | 14.000000 | ... | 0.000000 | 8000.000000 | 36.000000 | 9.430000 | 256.040000 | 6679.065000 | 928.700000 | 587.100000 | 221.757500 | 0.000000 |
| 50% | 6.000000 | 6.500000e+04 | 17.570000 | 1.130000e+05 | 19.720000 | 0.00000 | 34.000000 | 2003.00000 | 1.00000 | 21.000000 | ... | 0.000000 | 14500.000000 | 36.000000 | 11.980000 | 398.420000 | 12379.495000 | 1563.300000 | 984.990000 | 446.140000 | 0.000000 |
| 75% | 10.000000 | 9.500000e+04 | 25.002500 | 1.515455e+05 | 25.500000 | 0.00000 | 53.000000 | 2006.00000 | 3.00000 | 29.000000 | ... | 0.000000 | 24000.000000 | 60.000000 | 15.050000 | 644.690000 | 20690.182500 | 2616.005000 | 1694.555000 | 825.420000 | 0.000000 |
| max | 10.000000 | 2.300000e+06 | 469.090000 | 1.100000e+06 | 39.980000 | 13.00000 | 118.000000 | 2015.00000 | 29.00000 | 87.000000 | ... | 3.000000 | 40000.000000 | 60.000000 | 30.940000 | 1566.590000 | 40000.000000 | 41630.443684 | 40000.000000 | 4216.440000 | 52.980000 |
8 rows × 42 columns
Multiple regression: applied
Code
X = loans[['verified_income', 'debt_to_income', 'credit_util', 'bankruptcy', 'term', 'credit_checks', 'issue_month']]
y = loans['interest_rate']
X = pd.get_dummies(X, columns = ['verified_income', 'issue_month'], drop_first = True)
X.fillna(0, inplace=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state = 42)
X_train_with_const = sm.add_constant(X_train)
X_test_with_const = sm.add_constant(X_test)
X_train_with_const = X_train_with_const.astype(int)
X_test_with_const = X_test_with_const.astype(int)
model = sm.OLS(y_train, X_train_with_const).fit()
model_summary2 = model.summary2()
print(model_summary2) Results: Ordinary least squares
==============================================================================
Model: OLS Adj. R-squared: 0.191
Dependent Variable: interest_rate AIC: 46653.7930
Date: 2026-02-03 13:07 BIC: 46723.6650
No. Observations: 8000 Log-Likelihood: -23317.
Df Model: 9 F-statistic: 210.4
Df Residuals: 7990 Prob (F-statistic): 0.00
R-squared: 0.192 Scale: 19.937
------------------------------------------------------------------------------
Coef. Std.Err. t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 4.0713 0.2319 17.5583 0.0000 3.6167 4.5258
debt_to_income 0.0330 0.0033 9.8715 0.0000 0.0265 0.0396
credit_util 3.0409 0.4077 7.4585 0.0000 2.2417 3.8401
bankruptcy 0.5811 0.1543 3.7659 0.0002 0.2786 0.8836
term 0.1445 0.0046 31.5795 0.0000 0.1356 0.1535
credit_checks 0.2122 0.0211 10.0534 0.0000 0.1708 0.2535
verified_income_Source Verified 1.0041 0.1150 8.7304 0.0000 0.7787 1.2296
verified_income_Verified 2.4460 0.1355 18.0457 0.0000 2.1803 2.7117
issue_month_Jan-2018 -0.0778 0.1254 -0.6204 0.5350 -0.3236 0.1680
issue_month_Mar-2018 -0.0178 0.1233 -0.1445 0.8851 -0.2596 0.2239
------------------------------------------------------------------------------
Omnibus: 762.745 Durbin-Watson: 1.958
Prob(Omnibus): 0.000 Jarque-Bera (JB): 1001.147
Skew: 0.820 Prob(JB): 0.000
Kurtosis: 3.562 Condition No.: 398
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is
correctly specified.
\[\begin{aligned}
\widehat{\texttt{interest\_rate}} &= b_0 \\
&+ b_1 \times \texttt{verified\_income}_{\texttt{Source Verified}} \\
&+ b_2 \times \texttt{verified\_income}_{\texttt{Verified}} \\
&+ b_3 \times \texttt{debt\_to\_income} \\
&+ b_4 \times \texttt{credit\_util} \\
&+ b_5 \times \texttt{bankruptcy} \\
&+ b_6 \times \texttt{term} \\
&+ b_9 \times \texttt{credit\_checks} \\
&+ b_7 \times \texttt{issue\_month}_{\texttt{Jan-2018}} \\
&+ b_8 \times \texttt{issue\_month}_{\texttt{Mar-2018}}
\end{aligned}\]
Code
X_test_with_const = sm.add_constant(X_test)
predictions = model.predict(X_test_with_const)
predictions = pd.to_numeric(predictions, errors='coerce')
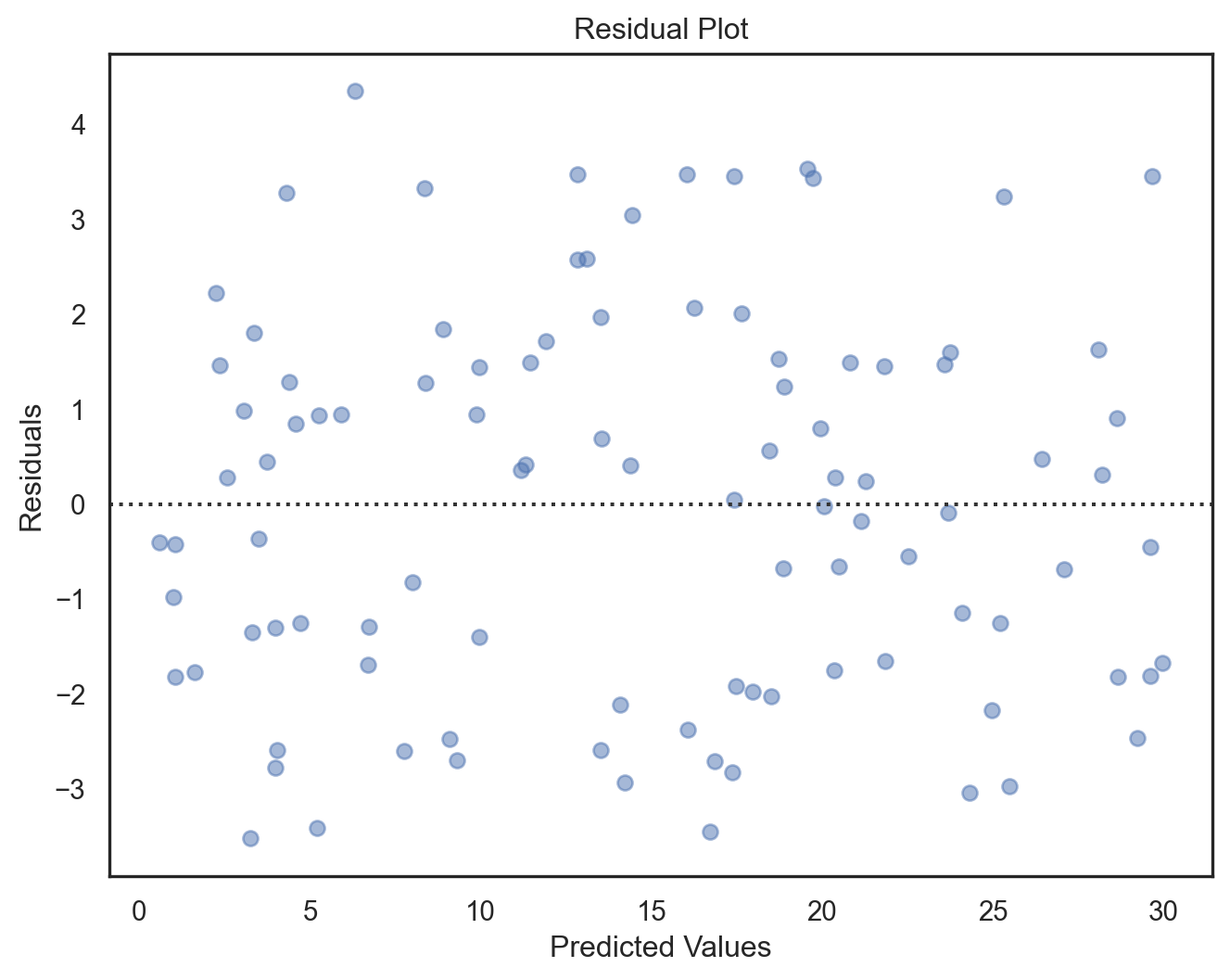
residuals = y_test - predictions
residuals = pd.to_numeric(residuals, errors='coerce').fillna(0)
# Plotting the residuals
sns.residplot(x = predictions, y = residuals)
plt.xlabel('Predicted Values')
plt.ylabel('Residuals')
plt.title('Residual Plot')
plt.show()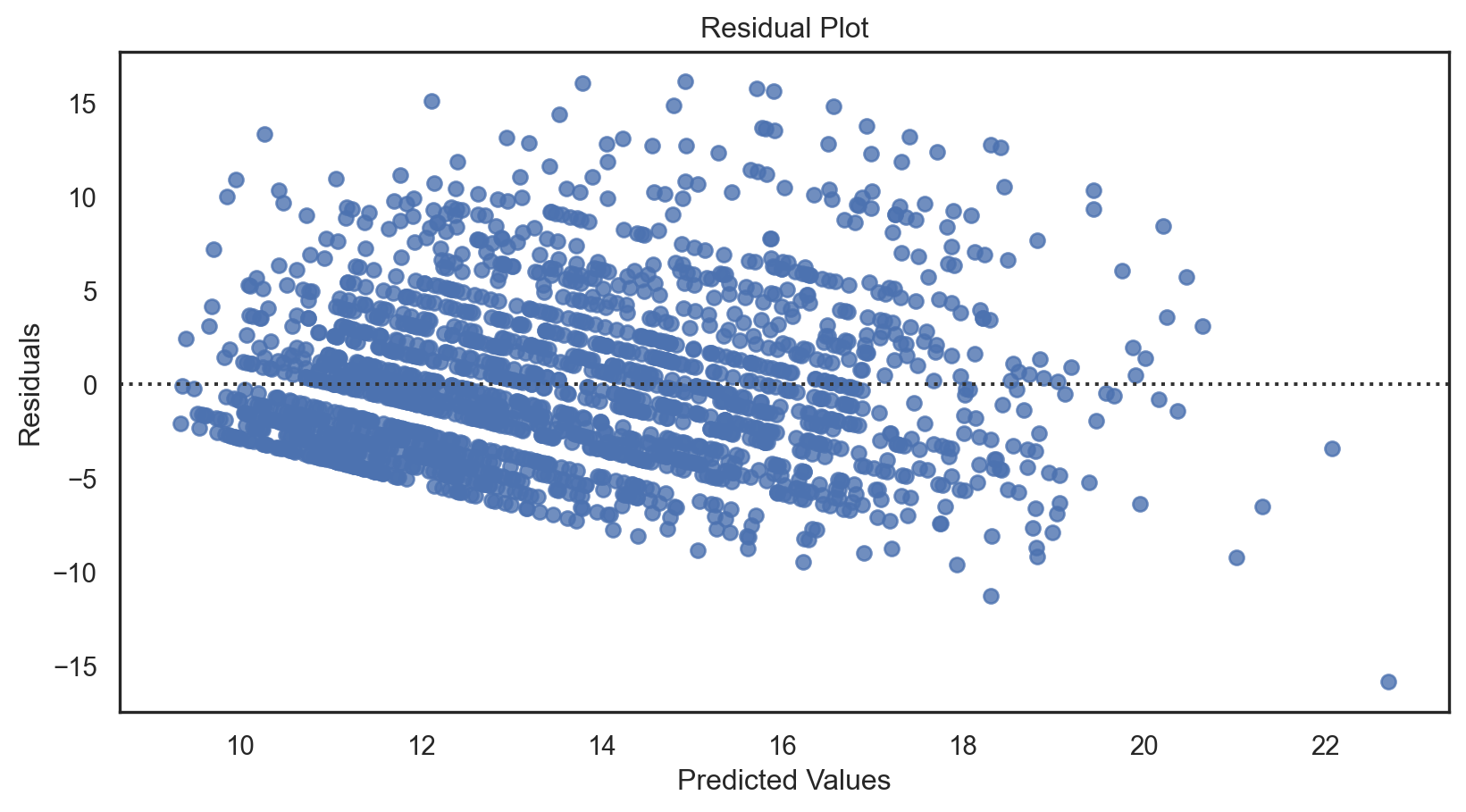
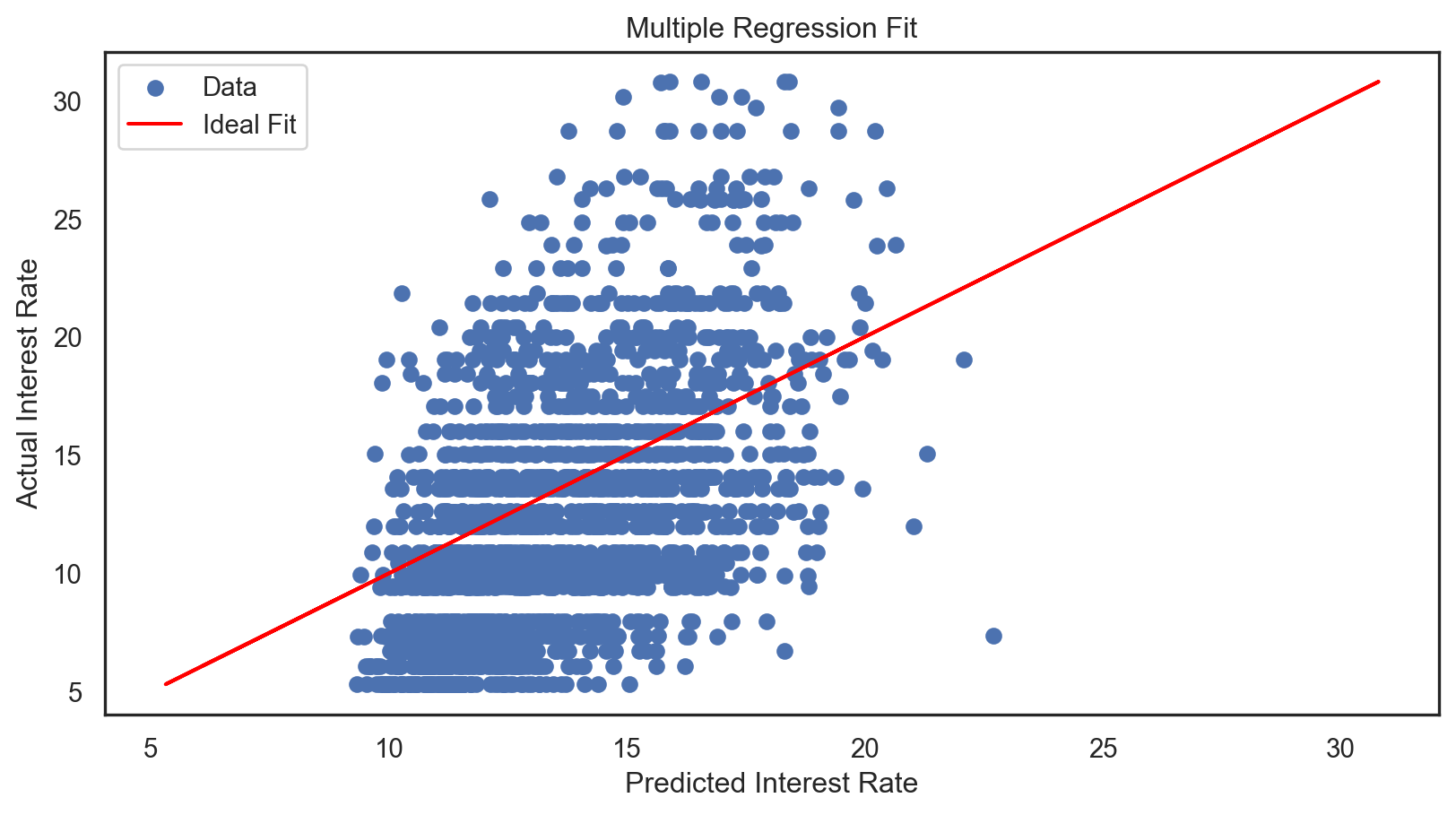
Conclusions
OLS regression is a great baseline model to compare against
Falls victim to collinearity, overly complex models
- Hence selection methods with model assessment
Best subset selection can overfit easier than stepwise selection
Stepwise selection is faster
Stepwise inflates Type I error with multiple testing…
![]()